InnoDB 索引
索引的代价
- 空间上的代价:一个数据页 16KB
- 时间上的代价
- 增删改时会修改 B+ 树索引
- 生成查询计划时一般只使用一个二级索引,如果建立的二级索引很多,查询优化器将花费很多时间分析使用各个二级索引的成本
- 回表的代价:在使用二级索引时,虽然得到的二级索引项是连续的,但是对应的主键不一定是连续的,它们所处的聚簇索引的页也不是连续的,导致回表时进行的是随机 IO,速度很慢
何时使用索引?
单表访问方式
const
使用主键或者唯一二级索引与一个常数进行等值比较时(当主键或者唯一二级索引由多个列组成时,要求每一个都与一个常数进行比较)。const 查询仅返回一条记录,速度极快
特别地,由于唯一二级索引中不限制 NULL 的数量,因此在与 NULL 进行比较时可能会返回多条记录,因此不适用于 const 查询
ref
使用普通的二级索引(即没有 UNIQUE 约束)进行等值查询时
当这个普通二级索引由多个列组成时,要求最左边的列必须是与常数(不可是 NULL !!!)等值查询,比如有一个索引为 (key_part1, key_part2, key_part3),下面的三个单表等值查询都可以使用 ref:
1 | |
需要指出的是,ref 查询可能需要对很多二级索引的记录进行回表,在需要回表的记录过多时,优化器也许不会再使用 ref 查询
ref_or_null
在 ref 的基础之上找出列中的值为 NULL 的记录,比如这个查询:
1 | |
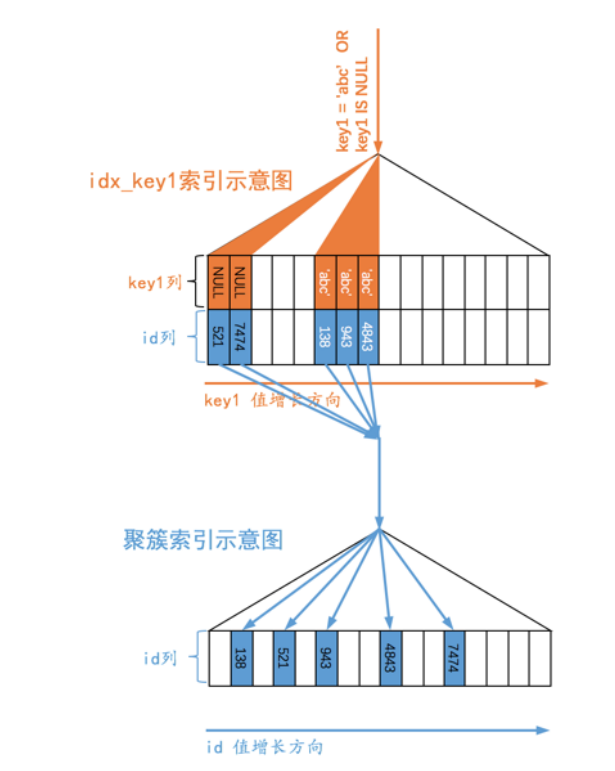
可见只是在 ref 的基础之上扫描了索引的最左边,所以还是比较快的(值为 NULL 的记录在索引的最左边)
range
使用索引查询时,对应的扫描区间为多个单点区间或范围区间时,称为 range,比如下面这个语句
1 | |
生成了两个单点区间和一个范围区间:[123, 123], [456, 456], [38, 79]
只有一个单点区间时不是 range,应该是 const 或者 ref
范围区间是负无穷到正无穷时也不是 range
index
回忆一下,我们之前建立了一个联合索引 (key_part1, key_part2, key_part3)。观察下面这个查询
1 | |
由于联合索引最左边的列不是等值查询,所以无法使用 ref。但是观察发现,这个查询是「索引覆盖」的,即要查询出的列正好是组成联合索引的列,此时不用回表,而且查询条件也是 key_part2 也是包含在联合索引中的。此时的策略是取出这个二级索引中的索引记录,判断在 key_part2 上是否满足查询条件。由于不用回表,所以还是比较快的
all
平平无奇的全表扫描
索引合并查询 Index Merge
前面说到在查询条件中有多个索引时,一般会选择成本最小的那个索引执行查询;在 MySQL 的 5.0 版本之后,在下面三种情况中,会合并多个索引进行查询
Intersection 索引合并
假设我们在 key1 上建立了二级索引 idx_key1,在 key2 上建立了二级索引 idx_key2。我们看下面这条查询:
1 | |
对于这个单表查询,由于存在索引,可以选择在 key1 上利用 idx_key1 进行 ref 单表查询,对于获取到的每个二级索引的叶节点进行回表操作,找出完整记录后再用 key2 的条件进行过滤;同理,也可以使用在 key2 上利用 idx_key2 进行 ref 单表查询,对于获取到的每个二级索引的叶节点进行回表操作,找出完整记录后再用 key1 的条件进行过滤。
但是其实还有第三种选项:同时使用 idx_key1 和 idx_key2 进行两次 ref,对于找到的两组二级索引的叶节点,使用主键值取交集(回忆:二级索引的叶子节点中是含有索引列和主键的!!!)。然后根据得到的叶子节点再去回表。由于访问二级索引的 B+ 树显著快于回表操作,因此这样减少了回表操作的索引合并方式是优于仅使用一个索引的单表查询的。
合并两个二级索引叶子节点的算法也十分「有趣」,本质上是一个双指针的算法题,类似于力扣第 88 题「合并两个有序数组
使用 Intersection 合并索引,必须要求从每个索引中获取到的二级索引记录都是按照主键值排序的!
如下面这个查询,即使我们已经建立了索引,但是由于 key1 > 'a' 的二级索引记录并不是按主键进行排序的,因此无法使用 Intersection 索引合并:
1 | |
Union 索引合并
对于类似于下面的查询:
1 | |
采取类似于 Intersection 索引合并的思路,我们利用两个二级索引得到两组二级索引叶子节点记录,然后对这两组记录在主键上取并集,然后再回表。同样,使用 Union 索引合并,要求从每个索引中获取到的二级索引记录按照主键值排序
####Sort-Union 索引合并
适当放宽 Union 索引合并的要求,如下面这个查询:
1 | |
根据两个二级索引获得的二级索引记录在主键上并不是有序的,但是我们可以对它们排序🤣,然后对两个排好序的区间进行合并,然后再回表
(MariaDB 中实现了 Sort-Intersection)
Links
MySQL :: MySQL 8.0 Reference Manual :: 15.6.2.1 Clustered and Secondary Indexes
MySQL :: MySQL 8.0 Reference Manual :: 15.1 Introduction to InnoDB
索引合并也许是有害的...The Optimization That (Often) Isn’t: Index Merge Intersection
后记
- 由于几乎没有索引的使用经验,所以这部分还是觉得学得干巴巴的,等有实际经验了再来完善下
- 看到索引合并的双指针算法时真的很激动,有种平时刷的算法题除了求职和锻炼思维外还是很实用的感觉!