6.5840 Lab3
Misc
- 即使是自己写项目代码,也请使用 git 进行管理。如果某次修改后,原先能通过的测试却通过不了了,没有版本记录真的很难 debug!
- 亟待掌握多线程 debug 的方法!
- 函数调用之间的同步和异步关系,如果是异步调用,可以使用 go 开启协程
- 如果一个用例执行时间过长(正常情况下的执行时间与实验文档中的时间接近),大概率是加锁解锁的逻辑没有处理好!
- 不要为了追求看似更好的并发性能在一个函数内部频繁地进行锁操作!一个函数一把大锁是比较理想的
Go
-
如何编写一个定期触发的函数(这个函数也叫 ticker)?
作为 Go 语言的新手,推荐
for 循环加 time.sleep的范式。time.ticker等需要一定的语言基础才能驾驭 -
之前学习 Go 时,学到了:在 main 函数中开启的协程,将在 main 函数结束后直接被撤销。但是除了 main 函数以外,A 函数开启的协程 B,它们之间的生命周期是无关的
-
如果在运行测试命令时,比如
go test -run PartA,加了一个 flag-race,那么,只要运行时检测到了数据竞争,测试均会通过,即使代码本身在不加-race时能通过同样的测试。一个好的实践是总是使用-race,并处理每一个警告的数据竞争 -
sync.Cond 的使用
sync.Cond是 Go 标准库中提供的一个条件变量工具,用于同步一组协程的执行。条件变量本质上是一个等待/通知机制:一个或多个协程等待某个条件满足,而另一个协程在条件满足时发送通知。-
创建 sync.Cond
条件变量需要与一个互斥锁(
sync.Mutex)或读写锁(sync.RWMutex)绑定使用。创建sync.Cond的代码示例如下:1
2var mu sync.Mutex
cond := sync.NewCond(&mu) -
Wait 方法
Wait方法用于等待条件变量的通知。在调用Wait之前,必须先获取锁(即在调用Wait前,锁必须是锁定状态)。调用Wait方法会自动释放锁,并且阻塞当前协程,直到其他协程调用Signal或Broadcast方法通知该条件变量。一旦当前协程接收到通知,Wait会自动重新尝试获取锁,如果成功获取锁后,Wait返回。 -
Signal 和 Broadcast 方法
Signal方法用于唤醒等待该条件变量的一个协程。如果有多个协程在等待,只唤醒一个(选择哪一个是不确定的)。Broadcast方法用于唤醒等待该条件变量的所有协程。
在调用
Signal或Broadcast之前,也必须先获取相同的锁。这样做是为了保证在修改条件并通知其他协程之间的操作是原子的,从而避免竞态条件。
-
Task
本次实验中,需要修改 raft/raft.go
Implementation
代码的整个框架从 server 的三种状态(candidate, follower, leader)出发,并仔细定义状态之间的迁移条件与相关函数
函数的命名风格上,后缀有 Safe 的说明在该函数开始执行时加锁,执行结束时解锁;后缀有 Unsafe 的说明在该函数内部不涉及对锁的操作
PartA
-
任务:实现基本的领导者选举和领导者发送心跳的功能
-
协程的使用
在最开始的实现中,向其他主机发起 RPC,在 for 循环中使用了函数调用,类似于:
1
2
3for xxx {
foo(xxx)
}这样的方法是错误的!首先,根据 Raft 论文的要求,与各个主机之间的 RPC 应该是同时进行。而上述的函数调用显然是顺序进行的;其次,这样的同步通信,如果遇到某个节点阻塞,那么整个系统都会阻塞这显然是不可接受的。正确的方法是使用 Go 中的协程
1
2
3for xxx {
go foo(xxx)
} -
ticker 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func (rf *Raft) electionTicker() {
for rf.killed() == false {
// Your code here (PartA)
// Check if a leader election should be started.
rf.mu.Lock()
if rf.role != Leader && time.Now().Sub(rf.electionTimeoutStart) >= rf.electionTimeoutDuration {
go rf.startElection()
}
rf.mu.Unlock()
// pause for a random amount of time between 50 and 350
// milliseconds.
ms := 50 + (rand.Int63() % 300)
time.Sleep(time.Duration(ms) * time.Millisecond)
}
}这个地方犯了一个错误,即将对于 rf.role!=Leader 的判断移到了第 2 行。这是错误的,因为不论 rf 是不是领导者,只要它没有被 kill,这个 ticker 函数是无论如何都要执行的。作为对比,下面这个 ticker 只有在 rf 是领导者时才能执行,所以可以在循环中使用 return 语句退出
1
2
3
4
5
6
7
8
9
10
11
12func (rf *Raft) appendEntriesTicker() {
for !rf.killed() {
rf.mu.Lock()
if rf.role != Leader {
rf.mu.Unlock()
return
}
rf.mu.Unlock()
go rf.startReplication()
time.Sleep(appendEntriesInterval)
}
}此外,上述两个 ticker 中均使用 go 关键字开启了协程,这是因为简单的函数调用会阻塞 ticker,这是不可接受的
-
处理数据竞争
在某一版本的代码中,通过不带
-race的测试,不过在使用-race后检测到了数据竞争。发现是在投票函数的实现中,多个并发的协程对一个整数型 votes 变量同时自增,造成数据竞争。最后将 votes 换为了一个容量很大的管道实现,因为管道是并发安全的
PartB
-
在本节对于投票规则的完善中,论文中的图 2 提到当前主机的 log 必须
at least as up-to-date ascandidate 的 log。至于如何具体定义这个up-to-date,其实在论文的后面部分才有定义。最开始时的定义其实是错误的:1
if args.LastLogTerm >= lastEntry.Term && args.LastLogIndex >= lastEntry.Index)在仔细阅读论文后可知,这里的比较其实是分为两步的:
- Term 更高的则更新
- Term 相同,Index 更高的则更新
因此正确的条件语句如下:
1
(args.LastLogTerm == lastEntry.Term && args.LastLogIndex >= lastEntry.Index) ||(args.LastLogTerm > lastEntry.Term)
PartC
-
Debug 时十分痛苦,最终修改了三处 PartB 中的错误实现
-
如果 PartA 和 PartB 的实现十分的 robust,本节的任务就是十分简单的持久化。不然的话,可能会像我一样,对之前的实现进行大改…尤其是 Figure 8(unreliable) 这个用例会十分难处理
-
代码中应尽可能少地进行锁的操作,比如最好将一个函数完全置于锁之中执行(有点类似管程的思想),若无必要,不要在中途释放锁!(一个例外则是,在进行 RPC 调用之前应该释放锁,因为这个 RPC 操作可能是很久才返回的)。此外,一些辅助函数内部也能不对锁进行操作就不对锁进行操作,而是由调用者进行加锁和解锁
-
如何更新 leader 的 commitIndex?
也许一种朴素的方式是枚举每一个下标
i,再枚举每一个主机peer,若match[peer] >= i,那么cnt++。最终若cnt > len(peers)/2,那么这个下标可以 commit。不过,运用简单的算法知识可知,如果我们对 match 数组进行升序排序,它的中位数(如果是偶数长度,那么选择靠左的那个中位数)一定满足大于等于至少一半的数组元素。实现如下:1
2
3
4
5
6
7func (rf *Raft) getMajorityIndexUnsafe() int {
tmp := make([]int, len(rf.matchIndex))
copy(tmp, rf.matchIndex) // avoid influencing the original slice when sorting
sort.Ints(tmp)
majorityIdx := (len(tmp) - 1) / 2
return tmp[majorityIdx] // in asending order
}如果使用这个算法,需要在遍历到自己时更新自己的 matchIndex,即:
1
2
3
4
5
6
7
8
9
10for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
rf.mu.Lock()
rf.matchIndex[i] = len(rf.Entries) - 1 // important
rf.nextIndex[i] = len(rf.Entries) // important
rf.mu.Unlock()
continue
}
go askToReplicate(i)
} -
实现了实验手册中提到的优化技巧,即每次日志同步失败时,不是 nextIndex–,而是根据 follower 返回的 XTerm 和 XIndex 信息去更新 nextIndex
PartD
-
首先需要明白,创建快照并不是 Raft 层需要做的事。在 Raft 的上层是服务层,比如后续需要实现的一个 KV 数据库。是由服务层创建快照后,再告知 Raft 层
-
在引入了快照机制后,
rf.Entries中的Entry.index与其位于Entries数组中的下标就不是一一对应的了!为了实现的简便,我们仍然引入哨兵机制,即无论如何,rf.Entries[0]一定是一个index为LastIncludedIndex、term为LastIncludedTerm、command为空的哨兵。rf.Entries[i]处存放的Entry,其index字段实际上是i+LastIncludedIndex;如果想要取出的entry.index = i,那么其实是对应rf.Entries[i-rf.LastIncludedIndex]因此,我们需要仔细考虑在前面部分对于
rf.Entries的所有访问! -
如果在这个部分的第一个用例测试时就陷入死锁,原因大概率是在之前的实现中,向
ApplyChannel中推送时还持有rf.mu。应该保证在推送前释放锁 -
需要指出的是,由于每次重启时,
rf.lastApplied被重置为rf.LastIncludedIndex,因此,那些位于rf.LastIncludedIndex后的日志将被重复应用。如果日志的操作满足幂等性,那么这一点是可以接受的;否则,可能需要额外的手段去控制不会重复应用已经应用过的日志,比如将lastApplied字段进行持久化。在后续的实验实现的 KV 数据库中,这一点是可以接受的,因为重复应用这些日志,只要是顺序执行的,那么最终的状态总是一致的 -
需要对数组访问进行下标检查。并且由于本节中引入了丢弃日志的机制,导致数组下标可能下越界。在本部分的头几个用例出现了下标下越界的情况,如果访问某个元素时下标下越界,在访问之前判断小于 0 直接
return当前函数即可;如果是访问多个元素获取切片时下标越界,此时返回一个 nil 即可 -
对于 snapshot 持久化的理解出现了重大偏差,直接导致最后两个用例一直过不去(卡了一晚上和一下午…)。首先重现灾难现场:
1
2
3
4var Snapshots []byte
if d.Decode(&Snapshots) != nil {
rf.Snapshots = Snapshots
}这段代码位于
readPersist方法中,目的是从持久化存储(虽然在本实验中,这个所谓的持久化存储是在内存中的。真正的持久化存储至少是以文件的形式保存)中恢复持久化的状态。但是,(菜菜的)我忽略了Snapshots的恢复是使用一个单独的函数rf.persister.ReadSnapshot();实现的!!!上述的实现导致读取的Snapshots一直是空的,无法通过最后两个用例。正确的实现如下:1
2
3
4
5if tmp := rf.persister.ReadSnapshot(); tmp != nil {
rf.Snapshots = tmp
rf.lastApplied = LastIncludedIndex // tricky!!!
rf.commitIndex = LastIncludedIndex
}
Result
PartA
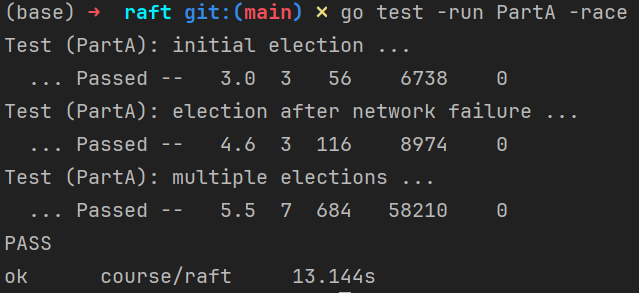
PartB
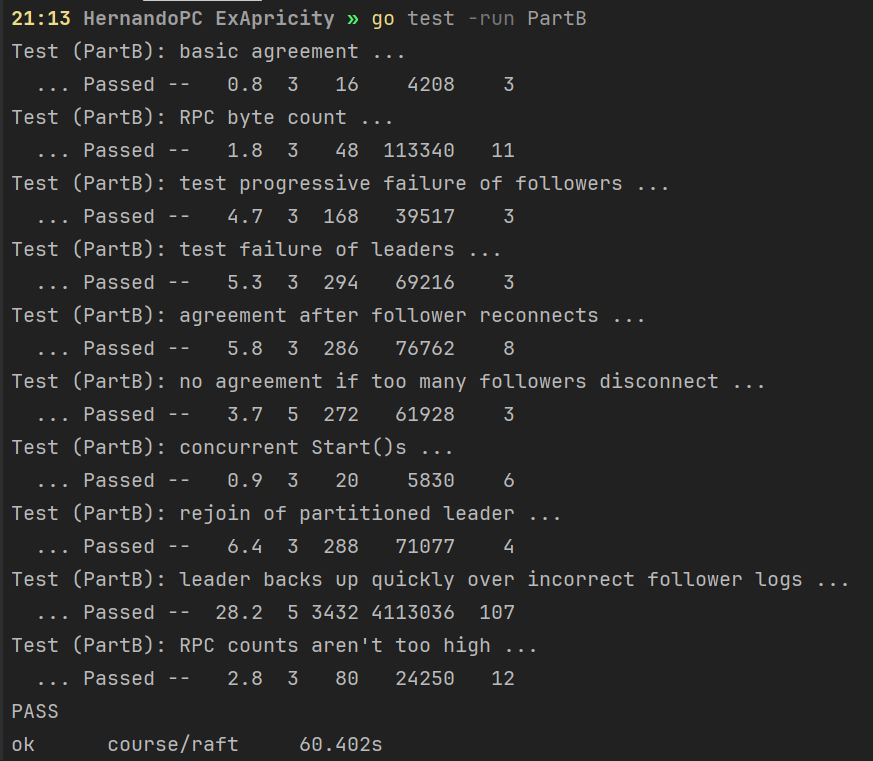
PartC
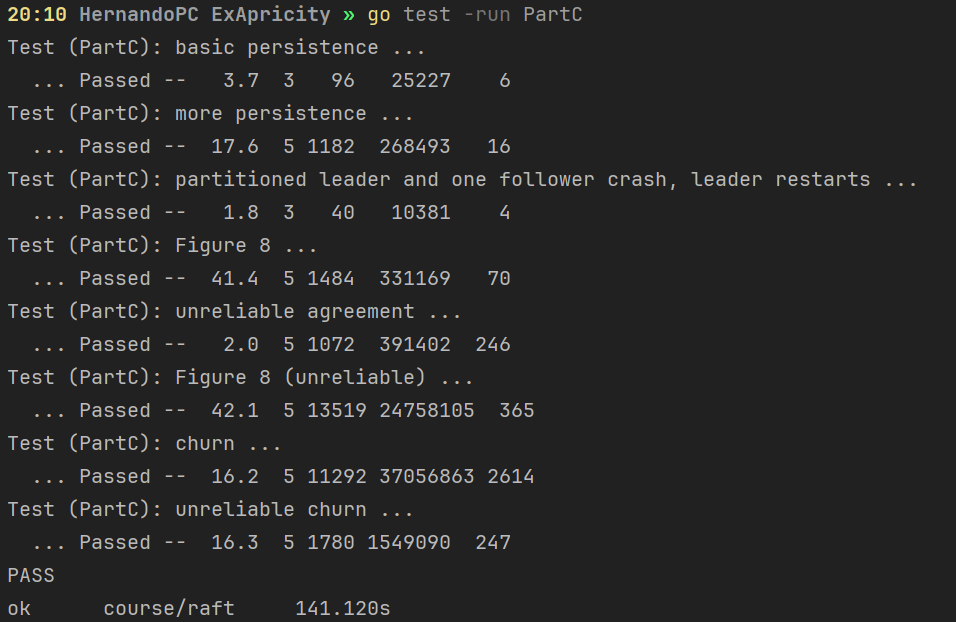
PartD
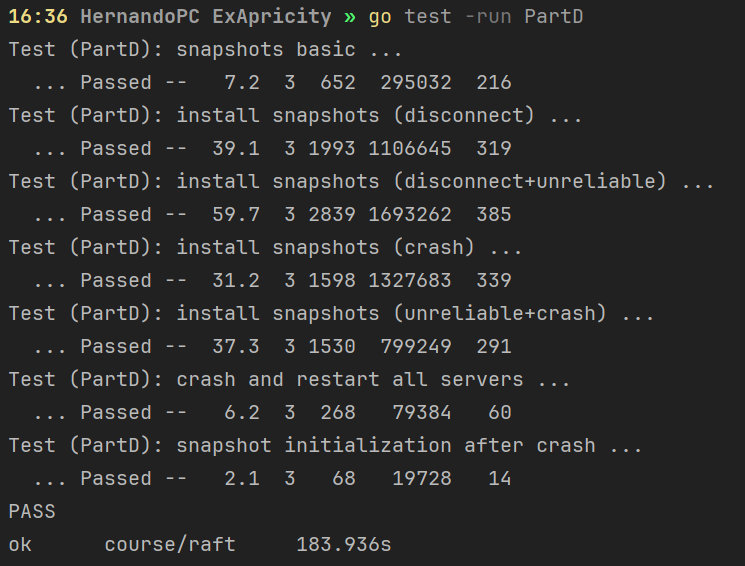
Overall
1 | |
Reflection
-
debug 的确很痛苦,但是的确也是没有仔细对照论文要求而导致的…我一度觉得在多线程 + 随机测试中 debug 就像陷入一个心理上的混沌状态…
-
对数组(Go 中也许切片更常用)的访问进行越界检查!
-
在进行可能阻塞的调用前应该及时释放持有的锁(比如发起 RPC、尝试读写一个通道等)
-
PartD 中对于代码的错误理解导致最后两个用例的 debug 时间长达 6H。在没有最终定位到根源错误时,由误打误撞地改了一些地方,此时最后两个用例可以过,但是前面能过的又过不了了,此时又花费时间去找出误认为前面存在的 bug。但是最终 bug 却在一个原以为不是那么重要的方法中
-
尚未进行大规模测试,并且改好 PartD 后,PartC 的某个测试偶有不过
Appendidx
大规模测试脚本(Windows 不可使用)